![]()
![]()
When the fitter is invoked from within UPSCALE's menu system, the data files for the current dataset are automatically loaded. However, the fitter may also be invoked from the UPSCALE home page or by giving its URL directly to your browser. In these cases, you must:
The fitter assumes that the files containing the data to which it is fitting are in a particular format. The UPSCALE menu system automatically creates files in this format. Here we discuss this format. The discussion is in two parts:
The UPSCALE menu system has two types of data files: current and backup data files. For both types, the user assigns a name for each variable when the dataset is created. Each variable name must:
If you have only a current dataset in UPSCALE's menu system, you wish to fit to it, and if you have, say, chosen the names ind, dep, and errDep as the names of the three variables in the dataset, then the file selection screen will look like this:
Please choose one of the following.You have a current dataset:
You may instead use any file you want:
|
You would then click on the first entry, labelled current dataset to choose it. The other two entries in the above example screen are discussed later in this page.
Technical note: a current dataset is made up of two files. The first file, named var.names, contains the names of the variables, separated by tabs; there may be up to eight different variables. The second file, named data.val, contains the data in columns of ASCII numbers corresponding to the variables names in the var.names file.
Backup data also has variable names associated with the data, but also contains a title that is assigned by the user. If, for example, you have two backup datasets but do not have a current dataset, the file selection screen will look like this:
Please choose one of the following.You have the following backed up datasets:
You may instead use any file you want:
|
You would choose either the "test dataset" or the "Boyle's Law data" in the above by clicking on it.
Technical note: the file formats for backup data is similar to a current dataset. The variable name file is named var.bak.n, where n is an integer between 1 and 8. The data itself is in an ASCII file named data.bak.n. The title of the dataset is a one-line ASCII file named title.bak.n.
Click here to go to the top of this page.
The fitter can use datasets that were not created by or maintained within the menu system. The files can either exist on the UPSCALE server or on your local computer's hard disc; the location is chosen from the last two items in the file selection screen. If you do not have any datasets created within the UPSCALE menu system, that screen will look like this:
Please choose one of the following.From where would you like to load your data?
|
Regardless of whether the file exists on UPSCALE's server or your own computer, the file should be in ASCII format; in Windows/DOS this format is sometimes called text and has a filename extension .txt. For example, if the data consists of x,y pairs and you have five data points, the data file could look like:
1 23 1.5 31.4 2.1 45.4 3.07 52.7 4.95 1.062e2
The last data point has values 4.95, 106.2.
The name of the file is arbitrary, and can be created by any number of tools including a simple text editor. In what follows we will assume that the file is named myData.
In setting up the fit, you will use variable names to identify the dependent and independent variables of the fit and, possibly, the errors in those variables. You may find it convenient to assign your own names to the variables. To do this create a second file containing a single line that names the variables, separated by tabs. The variable names must:
Say we have two variables in the dataset, and wish to name them press and vol respectively. Then the variable name file would look like:
press vol
In what follows, we shall assume that this file is named myVars.
![]() Warning: all files and directories that are to be
selected by this program must be readable by the world. For UNIX/Linux type
file systems, this means readable by "other" groups. This is the default for
files and directories created by student accounts on UPSCALE.
Warning: all files and directories that are to be
selected by this program must be readable by the world. For UNIX/Linux type
file systems, this means readable by "other" groups. This is the default for
files and directories created by student accounts on UPSCALE.
Technical note: If you choose file names that correspond to those created by the menu system, such as data.val and var.names respectively, the file selection system will recognise them automatically.
Choosing your directories on UPSCALE could lead to a file selection screen like this:
VARIABLE NAMESPlease choose the file containing your variable names.If you don't have a variable names file, then click here and I'll make up names for your variables. Index of /student/x/a/xacef (your home directory; 3 files or subdirectories)
|
Note that the above screen is to choose the file that names the variables, which is myVars in our example. If you choose the line in the above screen that says:
|
If you don't have a variable names file, then click here and I'll make up names for your variables. |
then the program will generate names var1, var2, etc. which you will use in setting up your fit.
Let us assume you chose your variable name file myVars above. Then the next screen looks like this:
DATA VALUESPlease choose the file containing your data.You chose /student/x/a/xacef/myVars (press, vol) for your variable names. Index of /student/x/a/xacef (your home directory; 3 files or subdirectories)
|
Now you would choose the file that contains the data, which is myData in our example. Note that the screen has also processed the variable name file and lists the variable names.
If you change the files in your directories and wish to "refresh" the listing, use the Reload button on your browser.
By default, a dataset contains two files. One contains the names of the variables, and the second contains the data itself. The variable names must:
The data file is an ASCII or text file in which each data point has numbers corresponding to the variables.
You may create these files in any manner that you wish. Windows users, for example, might choose to create text files using Notepad
The screen that the system presents you to choose the files looks like this:
Please Provide the variable names file and the data values file |
Note that the file naming the variables is optional. If you choose only a file that contains the data values and press the Submit Query button, the program will look in the data file to determine the number of variables, and will generate names var1, var2 etc. which you will use in setting up the fit.
When you choose to browse for one of the files, what sort of dialog box you are given depends on the particular computer you are using. Here is an example of what you might see under Windows:
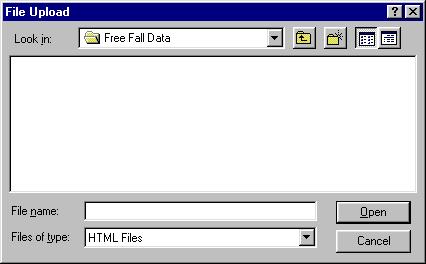
![]() Note that we are in some directory named Free Fall
Data, but no files appear. The problem is that by default this dialog
window looks for HTML Files, as can be seen by looking at the bottom of
the window; this behavior is a consequence of the way Windows and JavaScript
interact, not the interface to the fitter.
Note that we are in some directory named Free Fall
Data, but no files appear. The problem is that by default this dialog
window looks for HTML Files, as can be seen by looking at the bottom of
the window; this behavior is a consequence of the way Windows and JavaScript
interact, not the interface to the fitter.
Using the pulldown menu to choose all file types might make the window look like this:

Click here to go to the top of this page.
![]()
![]()
This help document is Copyright © 1999 David M. Harrison. The sample screens of the fit interface are Copyright © 1999 Solomon R.C. Douglas and David M. Harrison, except for the File Upload window snapshots. This is version 1.9 of the help document, date (m/d/y) 12/16/99.